Pleased to announce that we’ve now added Azure storage support to all the dbatools commands that copy databases around. This is part of our march towards full support for migrating on premise SQL Instances to Azure SQL Managed Instances
These changes also make it much much simpler to copy or migrate databases across SQL Server instances in different Active Directory domains.
Prerequisites
The features in this post are available in dbatool’s main production branch from version 0.9.807 onwards
You’ll need an Azure Storage account set up, previous blog posts on doing that can be found at:
- Creating Azure Blob storage account for SQL Server backup and restore via the portal
- Creating Azure Blob storage account for SQL Server backup and restore with PowerShell
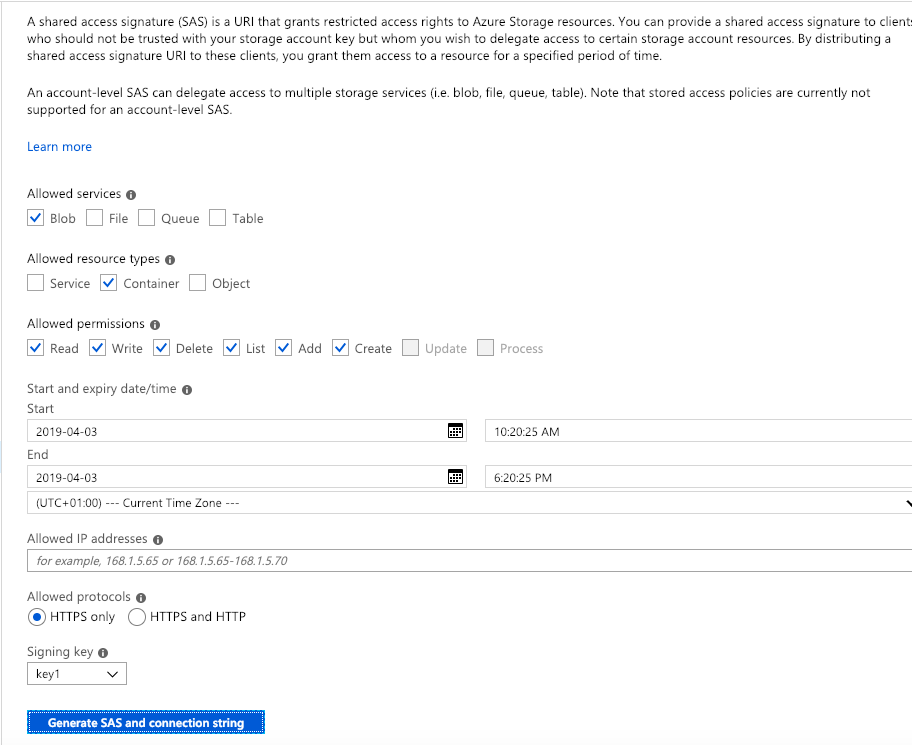
I’d highly recommend you use the Shared Access Signature method. 2 main reasons:
- Access Key auth is deprecated in SQL Server 2016+
- You can’t stripe or use mutiple storage accounts with Access Keys, but you can with Shared Access Signatures
Copy-DbaDatabase to Azure Managed Instance
So now you’ve got credentials on the source and destination instances, and a working storage account you’re ready to use Copy-DbaDatabase to move your database up to a Managed instance.
If you’re using Shared Access Secrets, then it’s a simple as using your storage account URL as the SharedPath:
$copyParams = @{
Source = "Server1"
Destination = "MyNewMI.public.cus29s972e4513d6.database.windows.net,3342"
DestinationCredential = $cre
SharedPath = "https://azblogdemo.blob.core.windows.net/sql"
BackupRestore = $True
}
Copy-DbaDatabase @copyParams
The only difference is that you now pass in the URL to your blob storage account rather than a UNC path to SharedPath
If you are using Access Keys, then you will need to pass the name of the SQL credential holding them in via the AzureCredential parameter
$copyParams = @{
Source = "Server1"
Destination = "MyNewMI.public.cus29s972e4513d6.database.windows.net,3342"
DestinationCredential = $cre
SharedPath = "https://azblogdemo.blob.core.windows.net/sql"
BackupRestore = $True
AzureCredential = "azblogdemo"
}
Copy-DbaDatabase @copyParams
All the other parameters you’d use with Copy-DbaDatabase other than ReuseSourceFolderStructure are available. That one’s not used as Managed Instances don’t allow user to specify paths
You may still get errors when copying certain databases. At the moment we’re not checking all the internal features of a database to make sure they are compatible with Azure SQL Managed Instances.
Start-DbaMigration with Azure Managed Instances
With Copy-DbaDatabase now supporting Managed Instances we can also start making Start-DbaMigration supporting them as well.
This is a preview of where we’re going as this particular command has more moving pieces that we need to make sure are properly compliant with the differences between on premise instances and Managed Instances as linked to above.
The sections working so far are:
- Copy-DbaDatabase, as explained above
- Copy-DbaLogin, this will copy SQL Server logins across but not Windows logins as they are not supported in MI yet
Bonus news for cross domain transfers
A common query on the #dbatools channel on SQL Community is how to copy a database or migrate an instance between 2 SQL Instances in different Active Directory domains with no trust relationship. The SQL Server connection is fairly simple as we can use SQL Server Logins, but the shared storage is trickier.
Permissions have to be very loose, and deciding how to sort the networking out can take a while
The good news is that using Azure Storage get’s around all of those issues. Create yourself an account, create the credentials on the source and destination instances and you’re good to go.
It’s all secure. The backups are encrypted on Azure Storage, and are only accessible to those people you allow (even Microsoft can’t see them unless you give them your keys). All the file transfer is done under 2048 bit SSL encryption. Which makes it safer than having a non domain joined sever with a share opened up to everyone/everyone
Wrap up
This is iteration one in a process that we hope will make migrating to a Managed Instance as easy as we’ve made migrating across SQL instances in your own Data Centres.
Please feedback any errors or issues you come across, and we’d love to hear you feedback and ideas for improvements..
Feel free to leave them in the comment below, or drop them in to the #dbatools channel on SQL Community, or raise an issue on Github